Recent 3D computed tomography (CT) vision–language models align volumes with reports via contrastive pretraining, but typically rely on limited public data and provide only coarse global supervision. We train a 3D CT vision–language model on 98k report–volume pairs (50k patients) collected at a single hospital, combined with public datasets, using SigLIP-style contrastive pretraining together with prompt-based disease supervision in the shared vision–text embedding space. On CT-RATE, our model achieves state-of-the-art text-to-image retrieval (R@10 31.5 vs. 22.2) and competitive disease classification (AUC 83.8 vs. 83.8), with consistent results on Rad-ChestCT (AUC 77.0 vs. 77.3).
We further observe that radiologists routinely reference specific images within their reports (e.g., “series X, image Y”), linking textual descriptions to precise axial locations. We automatically mine 262k such snippet–slice pairs and introduce the task of intra-scan snippet localization—predicting the axial depth referred to by a text snippet—reducing mean absolute error to 36.3 mm at 12 mm feature resolution, compared with 67.0 mm for the best baseline. Adding this localization objective leaves retrieval and classification broadly unchanged within confidence bounds, yielding a single unified model for retrieval, classification, and intra-scan grounding.
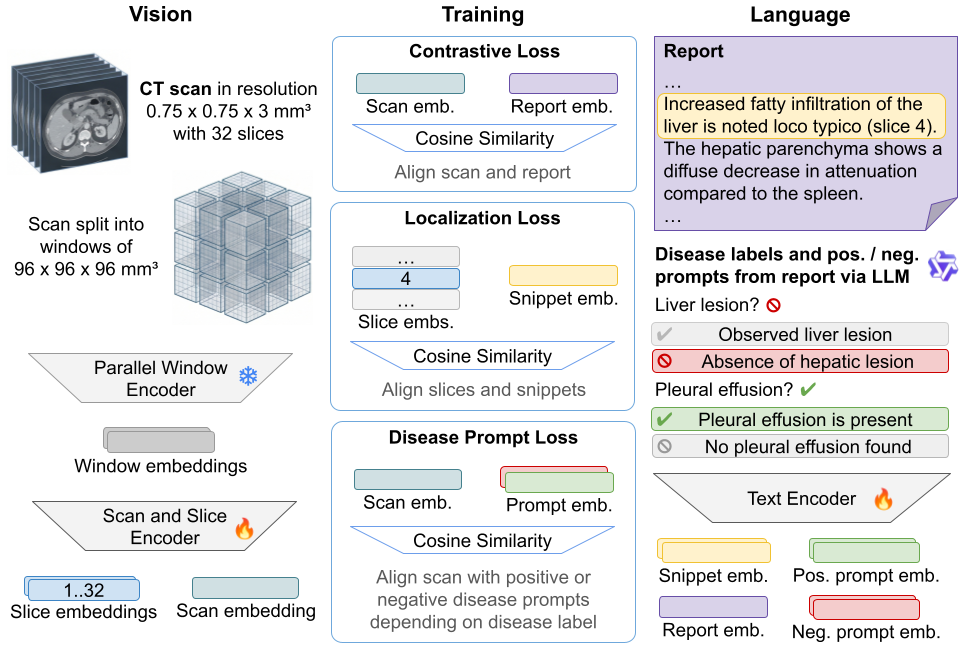
Dataset. We collect 97,760 report–volume pairs from 50,474 patients at a single hospital, spanning 13 years of clinical practice and covering chest (46%), abdomen (22%), and combined chest–abdomen (33%) studies. Reports are anonymized and translated to English using Gemma 3 27B. Using the RATE protocol, we extract 93 chest and 226 abdomen binary findings per report via LLM-based question answering. We additionally mine 261,800 snippet–slice pairs by extracting series/image references that radiologists embed in their reports (e.g., “hepatic lesion, see series 4, image 38”), achieving 99.4% precision and 90.2% recall.
Architecture. RadFinder builds on the pretrained SPECTRE model with a two-stage vision encoder: a frozen ViT-Large local backbone processes 128×128×32 voxel windows, and a trainable 4-layer global feature combiner aggregates window-level features. The text encoder is Qwen3-Embedding (0.6B) with LoRA adapters. SigLIP projection heads map both modalities to a 512-dim shared space.
Training objectives. We optimize three losses jointly: (1) a global SigLIP contrastive loss aligning full volumes with full reports; (2) a prompt-based disease loss that represents binary disease labels as positive/negative text prompts and supervises classification via BCE in the shared embedding space; and (3) an intra-scan localization loss that aligns text snippets with their referenced axial depth positions using within-scan negatives and Gaussian soft targets at 12 mm resolution.
RadFinder achieves state-of-the-art text-to-image retrieval on CT-RATE (R@10 31.5, up from 22.2) and on Merlin (R@1 69.0, up from 59.4), and competitive disease classification (AUC 83.8 on CT-RATE, 77.0 on Rad-ChestCT), matching the best prior methods within confidence bounds. Training on the internal RefCT dataset alone already surpasses all published baselines on retrieval, demonstrating strong cross-dataset transfer.
For the novel task of intra-scan snippet localization, RadFinder achieves MAE 36.3 mm at 12 mm feature resolution — nearly halving the error of the best baseline (67.0 mm). This localization objective can be trained jointly with the global objectives without degrading retrieval or classification.
This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) 417962828, 539134284 – through EFRE (FEIH_2698644) and the state of Baden-Württemberg, and 499552394 – SFB 1597 – Small Data.
@misc{ging2026radfinder,
author = {Simon Ging and Philipp Arnold and Sebastian Walter and Hani Alnahas and Hannah Bast and Elmar Kotter and Jiancheng Yang and Behzad Bozorgtabar and Thomas Brox},
title = {Learning to Read Where to Look: Disease-Aware Vision--Language Pretraining for 3D CT},
year = {2026},
note = {arXiv:2603.02026},
}